Web Scraping
Finding pages you want
robots.txt
When looking for a list of pages from a website you want to scrape. Start with the robots.txt file. You should be able
to find this file at the root domain such as https://example.com/robots.txt this file, if it exists, will show you a list
of pages that the site does not want you to scrape, or sets useragent limits for those pages. It's best to abide by these
requests as you don't want to get your IP address banned or ruin things for others. The robots.txt file should also show
you where the sitemap is located. Often it's just located at https://example.com/sitemap.xml but could have other names.
sitemap.xml
The sitemap is a literal list of webpages within that site. It may not be all of them, but it's at least the ones the site deems valuable enough to get indexed by search engines. The sitemap is usually xml but may be json or rss. You can use BeautifulSoup to parse this into a list of URLs you want to scrape.
Requests
Requests is often used to download webpages in their raw format, using a simple GET request.
import requests
url = "https://example.com"
## giving a user agent to requests is a simple and effective way to not get rejected as a bot
useragent = {'User-Agent': 'Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727)'}
response = requests.get(url, headers=useragent)
if response.status_code == 200: # or if response.ok
data_bytes = response.content # bytes, fine for bs4
data_str = response.text # string
data_json = response.json() # only if json-able, becomes python dict
else:
print(f"Error on {url} {response.status_code}, {response.text}")
from bs4 import BeautifulSoup as bs
soup = bs(response.content, 'html.parser')
raw_page_text = soup.text # or soup.getText() both will probably have a lot of \n
p_tags = soup.find_all('p') # iterable
some_id = soup.find('div', {'id': 'target-id'}) # single/first value
requests
JSON tips
Websites load data in chunks and leave it up to your browser to assemble them properly, often some of those chunks are JSON files for a client-side Javascript framework to assemble. This is really convenient as if the data you need is located in those files, you could just scrape the file itself and convert directly to a python dictionary instead of downloading the entire page and parsing the HTML.
Open the browser dev tools and select the Network tab at the top, then select the Fetch/XHR tab a little below that. This will filter all the loaded resources by those that include JSON files. If you don't see any, leave dev tools window open and reload the page (ctrl+shift+r to reload cached data too) you should then see JSON resources. You can left click these and see a preview of the data which should allow you to go through and confirm the data you want is available. The Headers tab should also indicate what is needed to get the data but it's easier to just right click the file and open in a new tab, if the data is visible in the tab using a GET request with at most a useragent is probably all you'll need.
You can then use the URL to this resource in Requests to get the data and use response.json() to convert to a dictionary.
This is a huge benefit as the data is already formatted in a way that is easily worked with, and it also is significantly
faster and lighter than downloading the entire page and parsing with BeautifulSoup.
Using Copy as cURL
Sometimes there's a lot of requirements to be met before a server will provide you any data. A good way to handle this is to load the page normally in your browser and open the dev tools window. From there, locate the file you want to scrape and right click it, then select the copy dropdown and 'copy as cURL'
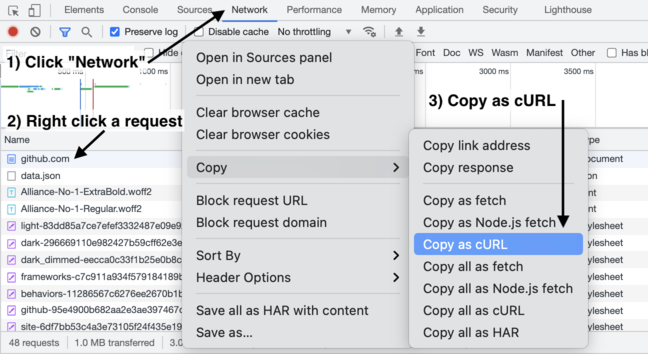 Here's a screenshot from cURL converter (linked below)
Here's a screenshot from cURL converter (linked below)
From there visit the cURL converter site and paste the data. This will conver the cURL command into Python (or other languages) and will include all the needed metadata/cookies etc to get the resource in python
For example copying this:
curl 'http://en.wikipedia.org/' \
-H 'Accept-Encoding: gzip, deflate, sdch' \
-H 'Accept-Language: en-US,en;q=0.8' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' \
-H 'Referer: http://www.wikipedia.org/' \
-H 'Connection: keep-alive' --compressed
import requests
headers = {
# 'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'http://www.wikipedia.org/',
'Connection': 'keep-alive',
}
response = requests.get('http://en.wikipedia.org/', headers=headers)
Getting creative with URLs
Take a look at the URLs you're parsing and look for the components they are made from. Do they use arguments? Is it a hashed mess? It can help you discover new resources or easier ways to iterate through the ones you have found. This is especially true of JSON files.
For example, below indicates that the data on the page starts at offset=0 and has count=25 values. We can loop through
and modify this URL to get new data, like increasing the count and then the offset by that count. Or we can change etfs
to another value, like commodities
https://finance.yahoo.com/etfs?offset=0&count=25
url_template = "https://finance.yahoo.com/etfs?offset={}&count={}"
new_count = 100
MAX_VALUE = 10_000 # check the page for the max
new_urls = [
url_template.format(offset, new_count)
for offset in range(0, MAX_VALUE, new_count)
]
new_urls list. But depending on the amount of requests you're making
and the size of the resource you're downloading, you may want to add a delay between requests.