Cool Snippets of Python Code
Here's some snippets of Code that are cool to reuse.
Python
I'm convinced that map, filter, lambda, zip, functools and itertools are some of the most
powerful functions/tools within Python and I'd like to expand my capabilities with them and have been trying to solve coding
challenges using them exclusively. Here's some scripts using these, while they aren't all super readable in one-line
form, they are fast and easy to make into lambda functions.
Table of Contents
- Handling Inputs
- Combining / Splitting
- Filtering Data
- Sorting Data
- Outputting Data
- Matrix Operations
- Prime Numbers
- Regex and Text Handling
- Ciphers / Encryption
- Data Conversions
- Misc Math
Handling Inputs
Input multiple lines (often used in competitions)
# Takes in space separated integers as strings, maps to ints
K, M = map(int, input().split())
# 5 100
# takes in multiple space separated values and creates a dictionary with index key and input as values
input_map = dict(enumerate(map(int, input().split())))
# {0: 5, 1: 100}
Combining/Splitting Data
Create a list of combined strings from multiple iterables
list(map(lambda a,b: f"{a}-{b}", ('apple', 'banana', 'cherry'), ('orange', 'lemon', 'pineapple')))
# ['apple-orange', 'banana-lemon', 'cherry-pineapple']
Join two lists together into list of tuples
zipped_list = list(zip([1,2,3], [4,5,6]))
# [(1, 4), (2, 5), (3, 6)]
Join two lists together into list of lists
zipped_list = list(map(list, zip([1,2,3], [4,5,6])))
# [[1, 4], [2, 5], [3, 6]]
Unzip a list of tuples
list(zip(*zipped_list))
# [(1, 2, 3), (4, 5, 6)]
Unzip list of lists
list(map(list, zip(*zipped_list)))
# [[1, 2, 3], [4, 5, 6]]
Split List into List of N sized Lists
A = [5, 4, 3, 2, 1, 0]
# split as is
split_list_n = lambda A, n: [A[i:i + n] for i in range(0, len(A), n)]
# [[5, 4, 3], [2, 1, 0]]
# sort the results before split
split_list_n_sorted = lambda A, n: [sorted(A[i:i+n]) for i in range(0, len(A), n)]
split_list_n(A, 3)
# [[3, 4, 5], [0, 1, 2]]
Reshape List into N Lists of Lists
A = [0, 1, 2, 3, 4, 5]
reshape = lambda A, n: [A[i:i + int(len(A)/n)] for i in range(0, len(A), int(len(A)/n))]
reshape(A, 2)
# [[0, 1, 2], [3, 4, 5]]
reshape(A, 3)
# [[0, 1], [2, 3], [4, 5]]
Create dictionary with key, values from two lists
dict(zip(['a','b','c'], [1,2,3]))
# {'a': 1, 'b': 2, 'c': 3}
Create dictionary with Index number keys
some_list = ['Alice', 'Liz', 'Bob']
# One-Line Statement Creating a Dict:
dict(enumerate(some_list))
# {0: 'Alice', 1: 'Liz', 2: 'Bob'}
# or as a function
indexed_dict = lambda some_list: dict(enumerate(some_list))
indexed_dict(some_list)
# {0: 'Alice', 1: 'Liz', 2: 'Bob'}
Extended Iterable Unpacking
first, *middle, last = [1, 2, 3, 4, 5]
print(first) # 1
print(middle) # [2, 3, 4]
print(last) # 5
*the_first_three, second_last, last = [1, 2, 3, 4, 5]
print(the_first_three) # [1, 2, 3]
print(second_last) # 4
print(last) # 5
Filtering Data
Filter a list by min value
ages = [5, 12, 17, 18, 24, 32]
[age for age in ages if age >= 18]
# or
list(filter(lambda age: age >= 18, ages))
# [18, 24, 32]
Sorting Data
Sort list of dictionaries by specific value
cars = [{'car': 'Ford', 'year': 2005}, {'car': 'Mitsubishi', 'year': 2000}, {'car': 'BMW', 'year': 2019}]
cars.sort(key = lambda x: x['year'])
# [{'car': 'Mitsubishi', 'year': 2000}, {'car': 'Ford', 'year': 2005}, {'car': 'VW', 'year': 2011}]
# pretty print sorted list of dictionaries
# Change order by adding `reverse=True` to `sorted()`
print(json.dumps(sorted(cars, key=lambda x: x['year']), indent=4))
# [
# {
# "car": "Mitsubishi",
# "year": 2000
# },
# {
# "car": "Ford",
# "year": 2005
# },
# {
# "car": "BMW",
# "year": 2019
# }
# ]
Sorting dictionary values
some_dict = {'a': 5, 'b': 8, 'c': 1}
sort_dict = lambda some_dict: dict(sorted(some_dict.items(), key=lambda x: x[1], reverse=True))
sort_dict(some_dict)
# {'b': 8, 'a': 5, 'c': 1}
Outputting Data
One liner to output a pretty JSON file
print(json.dumps(data, indent=4), file=open("path/to/data.json", 'w'))
One liner to output a JSONL file, run multiple times to keep adding
print(json.dumps(data), file=open("path/to/data.jsonl", 'a'))
CLI command to pretty print JSON in the terminal
python -m json.tool data.json
Matrix Operations
Create a list of sums of two lists or iterables
list_one, list_two = [1,2,3], [4,5,6]
cross_sum = lambda list_one, list_two: list(map(sum, zip(list_one, list_two)))
cross_sum(list_one, list_two)
# [5, 7, 9]
Get max value for each index number across multiple lists
list_one, list_two = [10,12,32], [14,5,16]
max_index_values = lambda list_one, list_two: list(map(max, zip(list_one, list_two)))
max_index_values(list_one, list_two)
# [14, 12, 32]
Get pair with smallest/largest difference between two iterables
# smallest
smallest_pair = min(some_list, key = lambda sub: abs(sub[1] - sub[0]))
# largest
largest_pair = max(some_list, key = lambda sub: abs(sub[1] + sub[0]))
Dot product of two lists

A, B = [2,7,1], [8,2,8]
# Method 1
dot = lambda A, B: sum(a * b for a, b in zip(A, B))
# Method 2
dot = lambda A, B: sum(map(lambda x: x[0] * x[1], zip(A, B)))
dot(A, B)
# 38
Matrix Product

A = [[1, 2],
[3, 4]]
B = [[5, 6],
[7, 8]]
matrix_product = lambda A, B: [[sum(ea * eb for ea, eb in zip(a, b)) for b in zip(*B)] for a in A]
matrix_product(A,B)
# [[19, 22],
# [43, 50]]
Matrix Addition

A = [[1, 2],
[3, 4]]
B = [[5, 6],
[7, 8]]
# Method 1
matrix_add = lambda A, B: list(map(lambda x, y: [a + b for a, b in zip(x, y)], A, B))
# Method 2
matrix_add = lambda a, b: [
list(map(sum, list(zip(*list(zip(a, b))[i])))) for i, v in enumerate(zip(a, b))
]
matrix_add(A, B)
# [[6, 8],
# [10, 12]]
Matrix Subtraction
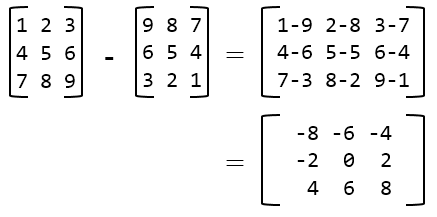
A = [[1,2,3],
[4,5,6],
[7,8,9]]
B = [[9,8,7],
[6,5,4],
[3,2,1]]
# Method 1
matrix_subtract = lambda A, B: list(map(lambda x, y: [a - b for a, b in zip(x, y)], A, B))
# Method 2
matrix_subtract = lambda A, B: [
list(map(lambda x: x[0] - x[1], list(zip(*list(zip(A, B))[i])))) for i, v in enumerate(zip(A, B))
]
matrix_subtract(A, B)
# [[-8, -6, -4],
# [-2, 0, 2],
# [ 4, 6, 8]]
Scalar Multiplication
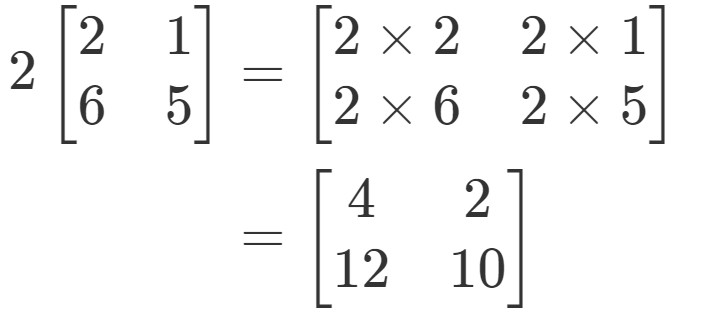
A = [[2,1],
[6,5]]
B = [1,2,3,4,5]
# Method 2 (Broken)
# scalar_multiply = lambda a, b: [
# list(map(lambda x: x[i] * b, zip(*a))) for i,v in enumerate(a)
# ]
# Method 1
scalar_multiply = lambda A, B: [[sum(ea * eb for ea, eb in zip(a, b)) for b in zip(*B)] for a in A] if isinstance(B, list) else [sum(ea * B for ea in a) for a in A]
scalar_multiply = (
lambda A, B: [[sum(ea * eb for ea, eb in zip(a, b)) for b in zip(*B)] for a in A]
if isinstance(B, list)
else [sum(ea * B for ea in a) for a in A]
)
scalar_multiply(A, 2)
# [[4, 2],
# [12, 10]]
scalar_multiply(B, 2)
Cosine Similarity
A, B = [3, 2, 0, 5], [1, 0, 0, 0]
dot = lambda A, B: sum(x * y for x, y in zip(A, B))
cosine_similarity = (lambda A, B: sum(x * y for x, y in zip(A, B)) / (sum([i**2 for i in A])**(1/2) * sum([i**2 for i in B])**(1/2)))
cosine_similarity(A, B)
# 0.48666426339228763
Jaccard Similarity
A = [1, 2, 3, 4]
B = [3, 4, 5, 6]
jaccard = lambda A, B: len(set(A).intersection(set(B))) / len(set(A).union(set(B)))
jaccard(A,B)
# 0.3333333333333333
jaccard('dog', 'doggy')
# 0.75
Jaccard Similarity (N Chunks) Testing, doesn't work well so far
A = [1, 2, 3, 4]
B = [3, 4, 5, 6]
jaccard_chunk = lambda A, B, size: len(
set([A[i : i + size] for i in range(0, len(A), size)]).intersection(
set([B[i : i + size] for i in range(0, len(B), size)])
)
) / len(
set([A[i : i + size] for i in range(0, len(A), size)]).union(
set([B[i : i + size] for i in range(0, len(B), size)])
)
)
Hamming Distance
A = [1,0,1,0,1,0,1,0]
B = [0,1,0,1,1,0,1,0]
hamming = lambda a, b: len(list(filter(lambda x: x[0] == x[1], zip(a,b))))
hamming(A, B)
# 4
Chebyshev Distance
A = [5, 8, 12, 9]
B = [3, 11, 10, 17]
chebyshev = lambda A, B: max([abs(a - b) for a,b in zip(A, B)])
chebyshev(A, B)
# 8
Mean Squared Errors
MSE formula = (1/n) * Σ(actual – forecast)^2
A, B = [41, 45, 49, 47, 44], [43.6, 44.4, 45.2, 46, 46.8]
mse = lambda A, B: sum(map(lambda x: (x[0] - x[1])**2, zip(A,B))) / len(A)
mse = lambda A, B: sum((a - b) ** 2 for a, b in zip(A, B)) / len(A)
mse(A,B)
# 6.079999999999994
Variance
A = [9, 2, 5, 4, 12, 7, 8, 11, 9, 3, 7, 4, 12, 5, 4, 10, 9, 6, 9, 4]
variance = lambda A: sum(map(lambda x: (x-sum(A)/len(A))**2, A))/len(A)
variance(A)
# 8.9
Sample Variance
A = [9, 2, 5, 4, 12, 7]
variance_sample = lambda A: sum(map(lambda x: (x-sum(A)/len(A)) ** 2, A)) / ((len(A)-1)/1)
variance_sample(A)
# 13.1
Standard Deviation
A = [9, 2, 5, 4, 12, 7, 8, 11, 9, 3, 7, 4, 12, 5, 4, 10, 9, 6, 9, 4]
std = lambda A: (sum(map(lambda x: (x-sum(A)/len(A))**2, A))/len(A))**0.5
std(A)
# 2.9832867780352594
Sample Standard Deviation (Bessel's Correction)
A = [9, 2, 5, 4, 12, 7, 8, 11, 9, 3, 7, 4, 12, 5, 4, 10, 9, 6, 9, 4]
std_sample = lambda A: (sum(map(lambda x: (x-sum(A)/len(A)) ** 2, A)) / ((len(A)-1)/1)) ** 0.5
std_sample(A)
# 3.6193922141707713
Sum of Squared Deviations (SDAM)
A = [4, 5, 9, 10]
sdam = lambda A: sum([(a - sum(A)/len(A))**2 for a in A])
Prime Numbers
Prime Number Check (Naive)
prime = lambda n: any([i for i in range(2, n) if n % i == 0]) != True
prime(27)
# False
primt(5)
# True
Prime Number Check (Optimized)
Optimization: checking if ending digit divisible by 2, reduced search space by limiting to square root of n
prime = (
lambda n: False
if n / 2 % 1 == 0
else any([i for i in range(2, int(n / 2) + 1) if n % i == 0]) != True
)
prime(27)
# False
prime(4_589_407)
# True
Mersenne Prime Number Finder
# Flat
prime = lambda n: False if int(str(n)[-1]) % 2 == 0 else any([i for i in range(2, int(n**0.5)+1) if n % i == 0]) != True
mersenne = lambda n: list(filter(lambda i: i is not None, list(map(lambda x: 2**x -1 if prime(2**x -1) else None, range(1, n+1)))))
# Black Format
prime = (
lambda n: False
if int(str(n)[-1]) % 2 == 0
else any([i for i in range(2, int(n / 2) + 1) if n % i == 0]) != True
)
mersenne = lambda n: list(
filter(
lambda i: i is not None,
list(map(lambda x: 2**x - 1 if prime(2**x - 1) else None, range(1, n + 1))),
)
)
mersenne(31)
# [1, 3, 7, 31, 127, 8191, 131071, 524287, 2147483647]
Sophie Germain Prime (WIP)
# Black Format
prime = (
lambda n: False
if n / 2 % 1 == 0
else any([i for i in range(2, int(n / 2) + 1) if n % i == 0]) != True
)
germain = lambda n: list(
filter(
lambda i: i is not None,
list(map(lambda x: x if all([prime(x), prime(2**x - 1)]) else None, range(1, n + 1))),
)
)
Regex and Text Handling
Regex for Zipcodes
re.search(r"^\d{5}(?:[-\s]\d{4})?$", some_str)
# ^ = Start of the string.
# \d{5} = Match 5 digits (for condition 1, 2, 3)
# (?:…) = Grouping
# [-\s] = Match a space (for condition 3) or a hyphen (for condition 2)
# \d{4} = Match 4 digits (for condition 2, 3)
# …? = The pattern before it is optional (for condition 1)
# $ = End of the string.
Regex for Phone Numbers
re.findall(r'[\+\(]?[1-9][0-9 .\-\(\)]{8,}[0-9]', some_str)
Regex for emails
re.findall(r'([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-.]+\.[a-zA-Z0-9-]+)', some_str)
Regex for urls
re.findall(r'(http|ftp|https):\/\/([\w\-_]+(?:(?:\.[\w\-_]+)+))([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])?', some_str)
Regex for numbers
re.findall(r'[1-9](?:\d{0,2})(?:,\d{3})*(?:\.\d*[1-9])?|0?\.\d*[1-9]|0', some_str)
Regex Scanner
import re
scanner=re.Scanner([
(r"[0-9]+", lambda scanner,token:("INTEGER", token)),
(r"[a-z_]+", lambda scanner,token:("IDENTIFIER", token)),
(r"[,.]+", lambda scanner,token:("PUNCTUATION", token)),
(r"\s+", None), # None == skip token.
])
results, remainder=scanner.scan("45 pigeons, 23 cows, 11 spiders.")
Quick Ratio (rough) without dependencies
quick = lambda a, b: len(list(filter(lambda x: x[0] == x[1], zip(a,b)))) / (len(a + b) / 2)
quick('dog', 'dog')
# 1.0
quick('dog', 'fog')
# 0.6666666666666666
quick('dog', 'cat')
# 0.0
quick('dog', 'dogmatic')
# 0.5454545454545454
Gestalt Pattern Matching
gestalt = lambda word, compared: (2 * (len([i[0] for i in zip(word, compared) if i[0] == i[1]])) / (len(word) + len(compared))) if isinstance(compared, str) else [{target: (2 * (len([i[0] for i in zip(word, target) if i[0] == i[1]])) / (len(word) + len(target)))} for target in compared]
Frequency map of character counts in a string
freq_map = lambda some_str: dict(zip(some_str, map(lambda x: some_str.count(x), some_str)))
freq_map('Hello World')
# {'H': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'W': 1, 'r': 1, 'd': 1}
Strip non alphabet characters from strings
remove_chars = lambda some_str: "".join([x for x in some_str if x.isalpha() or x == " "])
# or
remove_chars = lambda some_str: "".join((filter(lambda x: x.isalpha() or x == " ", some_str)))
remove_chars(")#$Hello3 World@$)")
# Hello World
Frequency map of word counts in a string (rough)
# Flat
word_count = lambda some_text: dict(zip("".join([x.lower() for x in some_text if x.isalpha() or x == " "]).split(), map(lambda x: some_text.count(x), some_text.split())))
# Black Format
word_count = lambda some_text: dict(
zip(
"".join([x.lower() for x in some_text if x.isalpha() or x == " "]).split(),
map(lambda x: some_text.count(x), some_text.split()),
)
)
word_count("the quick brown fox jumps over the lazy dog")
# {'the': 2, 'quick': 1, 'brown': 1, 'fox': 1, 'jumps': 1, 'over': 1, 'lazy': 1, 'dog': 1}
Spongebob Case text
convert text into SpOnGeBoB cAsE
# Flat
spongebob_case = lambda word: "".join(map(lambda i: i[1].upper() if i[0] % 2 != 0 else i[1].lower(), enumerate(word)))
spongebob_case = lambda word: "".join(s.upper() if i & 1 else s.lower() for i, s in enumerate(word))
# Black Format
spongebob_case = lambda word: "".join(
map(lambda i: i[1].upper() if i[0] % 2 != 0 else i[1].lower(), enumerate(word))
)
spongebob_case('hello world')
# hElLo wOrLd
Proper Nouns (naive)
proper_nouns = re.findall(r'\b(?:[A-Z][a-z]+)\b', text)
Verbs (naive)
verbs = re.findall(r'\b(?:[A-z]+ing|[A-z]+ed|[A-z]+en|[A-z]+s)\b', text)
Palindrome
word = "racecar"
palindrome = lambda word: word.lower() == "".join(reversed(word.lower()))
# or
palindrome = lambda word: word.lower() == word.lower()[::-1]
palindrome(word)
# True
Random Social Security Number
ssn = lambda: f"{str(random.randint(0,999)).zfill(3)}-{str(random.randint(0,99)).zfill(2)}-{str(random.randint(0,999)).zfill(4)}"
ssn()
# 885-92-0191
Random Phone number
phone = lambda: f"+{random.randint(1,99)}-{str(random.randint(0,999)).zfill(3)}-{str(random.randint(0,999)).zfill(2)}-{str(random.randint(0,999)).zfill(4)}"
phone()
# +4-267-62-0151
Ciphers / Encryption
ROT13 Cipher in a one line lambda
rot13 = lambda word: "".join(map(lambda l: chr(((ord(l)-84) % 26) + 97), word))
rot13('weattackatdawn')
# jrnggnpxngqnja
rot13('jrnggnpxngqnja')
# weattackatdawn
XOR Cipher
xor_cipher = lambda message, key: "".join([chr(ord(m) ^ ord(k)) for (m,k) in zip(message, key*len(message))])
cipher = xor_cipher('Hello world!', 's3cR3tP@$sW0rD')
xor_cipher(cipher, 's3cR3tP@$sW0rD')
One-Time Pad in one line lambda (kinda)
TODO: add support for mod operation
# Flat
otp = lambda message: list(zip(*list(map(lambda l: (chr(((ord(l[0])+l[1]))), l[1]), list(map(lambda x: (x, random.randint(1,10)),message))))))
# Black Format
otp = lambda message: list(
zip(
*list(
map(
lambda l: (chr(((ord(l[0]) + l[1]))), l[1]),
list(map(lambda x: (x, random.randint(1, 10)), message)),
)
)
)
)
# returns a list of two tuples, first is characters, second is keys
response = otp('Hello World!')
key = response[1]
# key = (3, 5, 1, 10, 10, 7, 2, 1, 10, 10, 5, 2)
cipher = "".join(response[0])
# cipher = Kjmvy'Yp|vi#
# decrypt
"".join(chr(ord(letter) - key) for letter, key in zip(cipher, key))
# 'Hello World!'
Data Conversions
Convert lists to tuple (Recursive)
Converting tuples or nested tuples into JSON changes tuples into lists, so loading back in would change the data types. This recursively goes through a list and converts inner lists into tuples.
# Flat
tuple_it = (lambda x: tuple(map(lambda i: tuple_it(i) if isinstance(i, list) else i, x)) if isinstance(x, list) else x)
# Black format
tuple_it = (
lambda x: tuple(
map(lambda i: tuple_it(i) if isinstance(i, list) else i, x)
)
if isinstance(x, list)
else x
)
data = ('apple', 'banana', 'cherry', ('this', 'that'), (('inner', 'deep'), 'stuff'))
data = json.dumps(data)
# '["apple", "banana", "cherry", ["this", "that"], [["inner", "deep"], "stuff"]]'
# Later on...
data = json.loads(data)
# ['apple', 'banana', 'cherry', ['this', 'that'], [['inner', 'deep'], 'stuff']]
data = tuple_it(data)
# ('apple', 'banana', 'cherry', ('this', 'that'), (('inner', 'deep'), 'stuff'))
Combinations
A = [1,2,3]
combination = lambda A: [[a] + b for i, a in enumerate(A) for b in (combination(A[i+1:]) or [[]])]
combination(A)
# [[1, 2, 3], [1, 3], [2, 3], [3]]
Misc Math
Factoral (Recursive)
factoral = lambda n: 1 if n <= 1 else n * factoral(n - 1)
print(factoral(10))
# 3628800
Mean
A = [99,86,87,88,111,86,103,87,94,78,77,85,86]
mean = lambda A: sum(A)/len(A)
mean(A)
# 89.76923076923077
Median
A = [99,86,87,88,111,86,103,87,94,78,77,85,86]
median = lambda A: sorted(A)[int(len(A)/2)]
median(A)
# 87
Mode
A = [99,86,87,88,111,86,103,87,94,78,77,85,86]
mode = lambda A: max(A, key=A.count)
mode(A)
# 86
Least Common item in List
A = [99,86,87,88,111,86,103,87,94,78,77,85,86]
least_common_item = lambda A: min(A, key=A.count)
least_common_item(A)
# 99
check if N is divisible by X AND Y
n_divisible = lambda n, x, y: all([divmod(n, x)[1] == 0, divmod(n, y)[1] == 0])
n_divisible(12, 2, 6)
# True
Get number of odd numbers below N
# Faster
odd_below = lambda n: len([x for x in range(n) if x % 2 != 0])
# or a bit slower
odd_below = lambda n: len(list(filter(lambda x: x % 2 != 0, range(n))))
odd_below(15)
# 7
Get number of even numbers below N
# Faster
even_below = lambda n: len([x for x in range(n) if x % 2 == 0])
# or a bit slower
even_below = lambda n: len(list(filter(lambda x: x % 2 == 0, range(n))))
even_below(15)
# 7
Greatest Common Denominator
a, b = 24503, 321
gcd = lambda a, b: a if b == 0 else gcd(b, a % b)
gcd(a, b)
# 107
Euler Totient
p, q = 7, 13
euler_totient = lambda p, q: (p-1) * (q-1)
euler_totient(p, q)
# 72
Remove Outliers
Filter list down by those within N standard deviations of the mean
A = [10, 8, 10, 8, 2, 7, 9, 3, 34, 9, 5, 9, 25]
# Mean is 10.692307692307692
remove_outliers = lambda A, n: list(filter(lambda x: (sum(A)/len(A) - n * (sum(map(lambda x: (x-sum(A)/len(A))**2, A))/len(A))**0.5) <= x <= (sum(A)/len(A) + n * (sum(map(lambda x: (x-sum(A)/len(A))**2, A))/len(A))**0.5), A))
remove_outliers(A, 2)
# [10, 8, 10, 8, 2, 7, 9, 3, 9, 5, 9, 25]
remove_outliers(A, 1)
# [10, 8, 10, 8, 7, 9, 3, 9, 5, 9]
remove_outliers(A, 0.25)
# [10, 10, 9, 9, 9]
Least Squares Regression
Calculate the least squares regression line given two lists
A = [2, 3, 5, 7, 9]
B = [4, 5, 7, 10, 15]
# Flat
lsr = lambda A, B: [(sum_ab * len(A) - sum_a * sum_b) / (sum_aa * len(A) - sum_a**2) * i + (sum_b - (sum_ab * len(A) - sum_a * sum_b) / (sum_aa * len(A) - sum_a**2) * sum_a) / len(A) for i, sum_a, sum_b, sum_aa, sum_ab in [(ai, sum(A), sum(B), sum([ai**2 for ai in A]), sum([ai * bi for ai, bi in zip(A, B)]),) for ai in A]]
# Black format
lsr = lambda A, B: [
(sum_ab * len(A) - sum_a * sum_b) / (sum_aa * len(A) - sum_a**2) * i
+ (
sum_b
- (sum_ab * len(A) - sum_a * sum_b) / (sum_aa * len(A) - sum_a**2) * sum_a
)
/ len(A)
for i, sum_a, sum_b, sum_aa, sum_ab in [
(
ai,
sum(A),
sum(B),
sum([ai**2 for ai in A]),
sum([ai * bi for ai, bi in zip(A, B)]),
)
for ai in A
]
]
lsr(A, B)
# [3.341463414634146, 4.859756097560975, 7.896341463414634, 10.932926829268293, 13.96951219512195]
Fisher Jenks Natural Breaks (Work in Progress)
A = [1500, 2100, 50, 20, 75, 1100, 950, 1300, 1400]
# Flat
jenks = lambda A: min(map(lambda x: {'split': x, 'value': sum([(sum([(ia - sum(i)/len(i))**2 for ia in i])) for i in x])}, [[sorted(A)[i:i+N] for i in range(0, len(A), N)] for N in range(2, len(A)+1)]), key = lambda k: k.get('value', None)).get('split')
# Black
jenks = lambda A: min(
map(
lambda x: {
"split": x,
"value": sum([(sum([(ia - sum(i) / len(i)) ** 2 for ia in i])) for i in x]),
},
[
[sorted(A)[i : i + N] for i in range(0, len(A), N)]
for N in range(2, len(A) + 1)
],
),
key=lambda k: k.get("value", None),
).get("split")
jenks(A)
# [[20, 50, 75], [950, 1100, 1300], [1400, 1500, 2100]]
jenks(A )
Distance Between Points (Pythagorean 2D and 3D space)
x = (9, 7)
y = (3, 2)
pythagorean = lambda x,y: sum(map(lambda i: (i[0] - i[1])**2, list(zip(x,y))))**0.5
pythagorean(x,y)
# 7.810249675906654
x = [8, 2, 6]
y = [3, 5, 7]
pythagorean(x, y)
# 5.916079783099616
Perceptron (WIP)
A = []
B = []
lsr = lambda A, B: [
(sum_ab * len(A) - sum_a * sum_b) / (sum_aa * len(A) - sum_a**2) * i
+ (
sum_b
- (sum_ab * len(A) - sum_a * sum_b) / (sum_aa * len(A) - sum_a**2) * sum_a
)
/ len(A)
for i, sum_a, sum_b, sum_aa, sum_ab in [
(
ai,
sum(A),
sum(B),
sum([ai**2 for ai in A]),
sum([ai * bi for ai, bi in zip(A, B)]),
)
for ai in A
]
]
Probability
A = [9, 2, 5, 4, 12, 7, 8, 11, 9, 3, 7, 4, 12, 5, 4, 10, 9, 6, 9, 4]
probability = lambda n, A: A.count(n)/len(A)
probability(4, A)
# 0.2
CLI commands
host a web server at current directory
python -m http.server
display documentation for a python module
python -m pydoc module
precompile python code to bytecode
python -m py_compile minimath.py